Comment nous avons utilisé les données de recherche Google, le traitement du langage et GPT-3 pour prévoir l'activité touristique
Antoine Herlin, 2023 February 21
Résumé
Dans cet article, nous montrons comment les données issues des recherches Google nous ont aidé à mieux prédire et comprendre l'activité touristique en Alsace.
Nous avons utilisé des outils linguistiques avancés d'OpenAI (embeddings models et GPT-3) pour classer, trier et extraire des informations pertinentes à partir d'une grande quantité de données sur les mots-clés des recherches Google.
Les résultats sont prometteurs et il sera intéressant de voir si des approches similaires peuvent également être utiles dans le cadre de projets plus vastes et pour d'autres secteurs.
Plus généralement, il s'agit également d'un exemple de la manière dont les nouveaux modèles de langage peuvent être utilisés pour automatiser des tâches intellectuelles simples et permettre de nouvelles applications.

Photo by Julien Verneaut on Unsplash
Contexte et objectifs
Notre objectif est de comprendre le passé récent et de prévoir le futur proche de l'activité touristique en Alsace. Dans cet exemple simple, nous nous concentrerons sur l'activité hôtelière.
Les données sur l'activité hôtelière sont disponibles publiquement auprès de l'Insee. Elles sont publiées mensuellement, généralement environ 40 jours après la fin de chaque mois.
Examinons les données récentes :
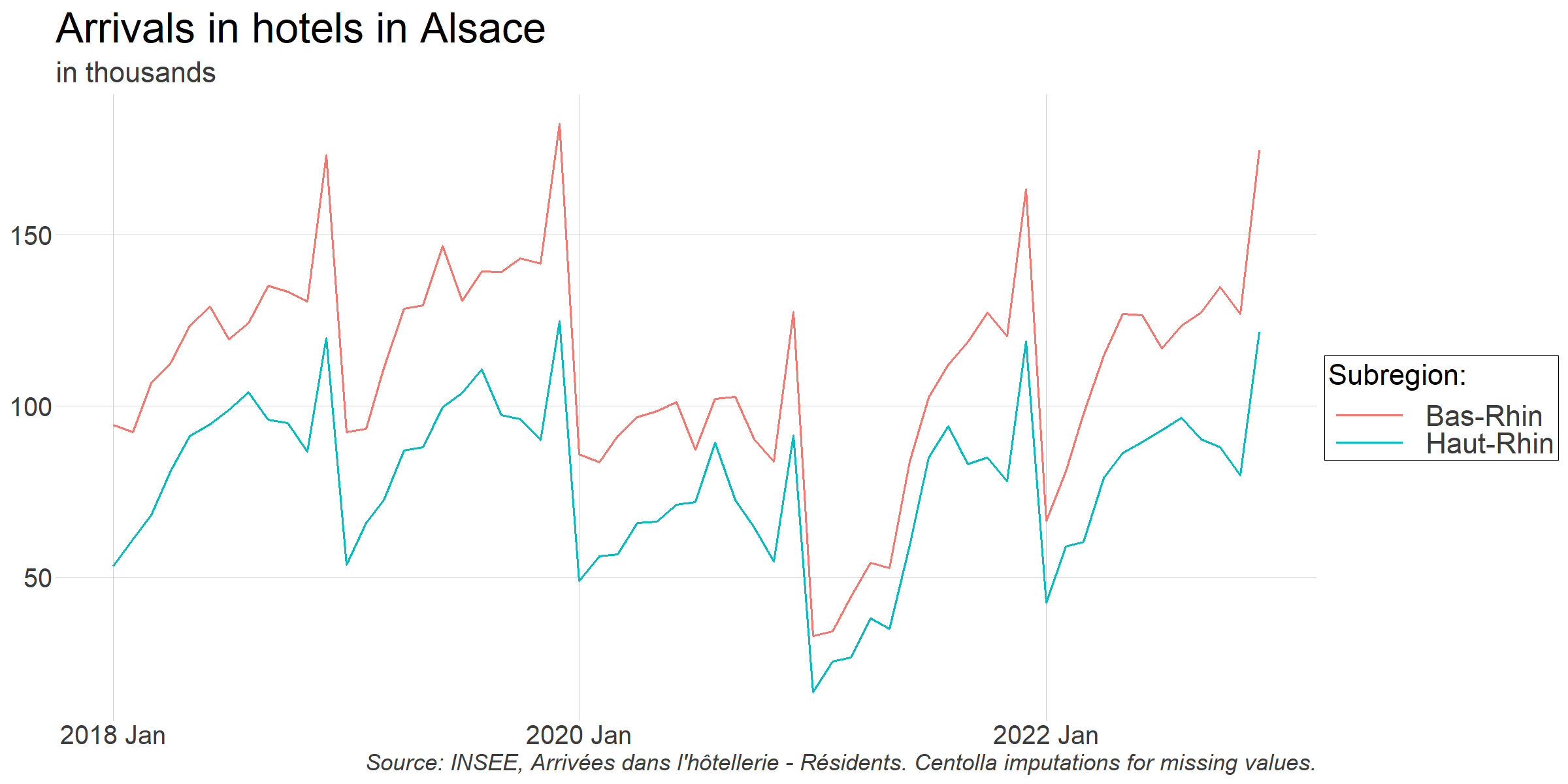
Nous pouvons remarquer qu'il y a beaucoup de variabilité dans la série !
- Tout d'abord, comme on pouvait s'y attendre, l'activité touristique est toujours très saisonnière. L'été est assez chargé tandis que le début de l'année ne l'est pas. Le gros pic de décembre est dû à des événements saisonniers qui attirent de nombreux touristes (marchés de Noël, en particulier à Strasbourg).
- Deuxièmement, on peut clairement voir l'impact de la pandémie et des confinements. Les réservations d'hôtels ont été beaucoup plus faibles que la normale depuis le début de l'année 2020 jusqu'à mi-2021.
La forte variabilité de cette série est intéressante pour cette exemple. Nous pourrons tester si les données des moteurs de recherche sont utiles pour expliquer les changements saisonniers, ainsi que la période spécifique de la pandémie.
Collecte de données des moteurs de recherche
On peut raisonnablement penser qu'il devrait y avoir une corrélation entre certaines requêtes de moteurs de recherche et les réservations d'hôtels. Parmi les personnes qui prévoient un voyage en Alsace, beaucoup sont en effet susceptibles de rechercher des termes tels que "hôtel Alsace" ou "hôtel Strasbourg".
Mais pour tester cette hypothèse, nous avons d'abord besoin de collecter des données.
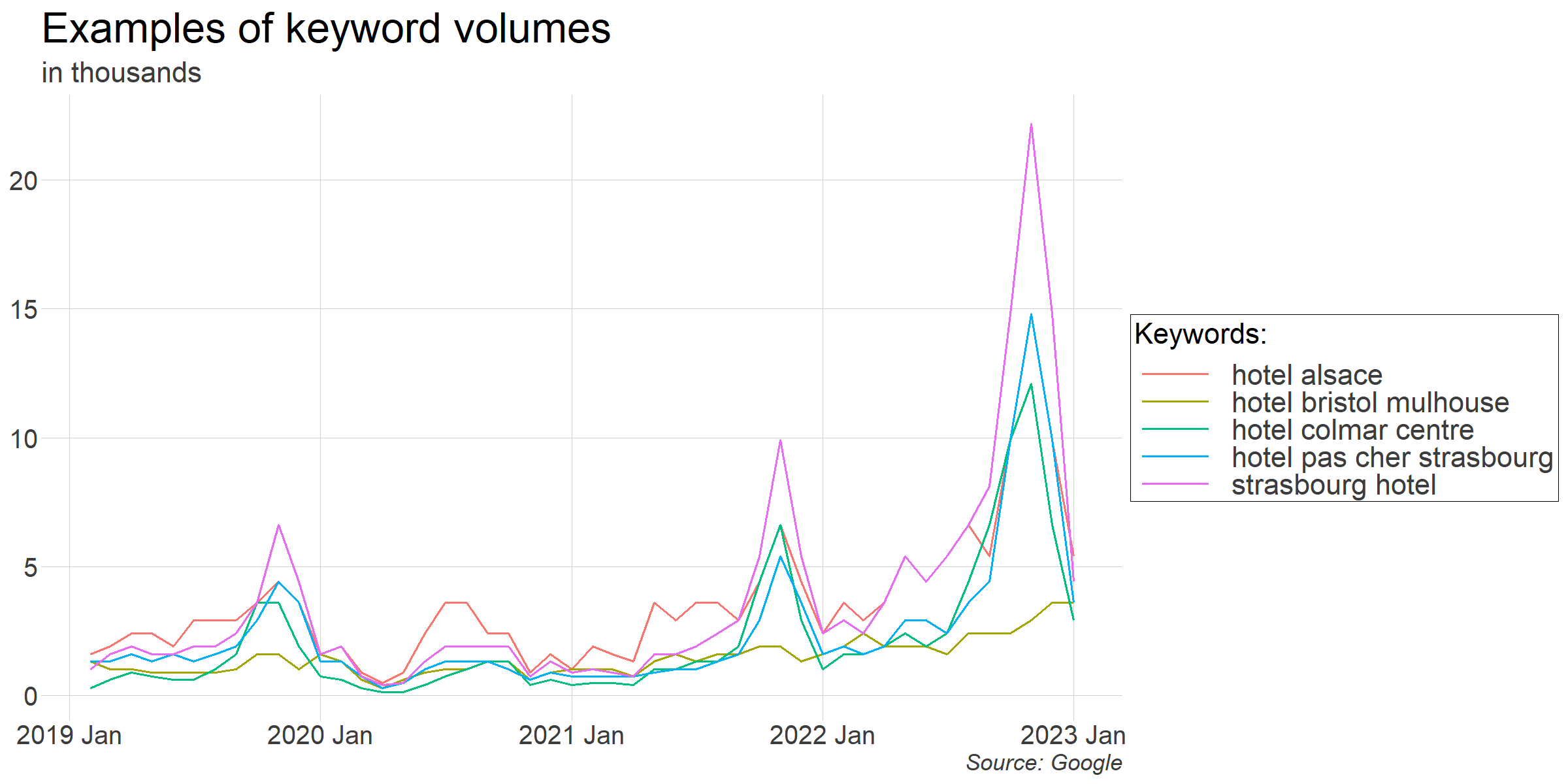
Il existe de nombreux outils qui aident à collecter des métriques pour un grand nombre de mots-clés (soit directement auprès de Google, soit en utilisant des applications tierces). Nous avons construit un premier échantillon de 10 000 mots-clés associés aux hôtels d'Alsace. À ce stade, nous n'avons pas besoin d'être trop spécifiques. Nous filtrerons plus tard les mots-clés qui semblent peu pertinents ou qui ne semblent pas utiles pour les prévisions.
Voici des exemples de volumes de recherche pour certains des mots-clés que nous avons obtenus :
Comment exploiter nos données de mots-clés ?
Maintenant que nous avons à notre disposition une grande quantité de données de mots-clés, le défi consiste à identifier celles qui sont réellement pertinentes pour notre objectif.
Pour trier les informations, on peut d'abord envisager d'utiliser des approches statistique qui nous permettraient de conserver spécifiquement les mots-clés qui améliorent les prévisions des modèles.
Cependant, il y a un risque élevé de surapprentissage dans notre cas, car nous avons beaucoup de données explicatives (les mots-clés) pour nettement moins d'observations (les mois de données dures). Cela veut dire qu'il serait facile de construire des modèles qui s'adaptent parfaitement au passé, mais qui ne parviennent pas à généraliser lorsqu'ils sont confrontés à de nouvelles données dans le futur.
Un moyen d'atténuer ce risque est d'introduire du jugement dans le processus de tri et de choisir spécifiquement des sous-ensembles de mots-clés qui semblent avoir un lien plausible avec les réservations d'hôtels. Cette tâche est assez simple pour les humains, mais lorsque qu'il faut la réaliser pour des milliers, voire des centaines de milliers de mots-clés, elle devient beaucoup trop chronophage.
Pour répondre à cette difficulté, nous avons décidé d'utiliser des outils de traitement de langage et des modèles de génération de langage dans notre projet. Ces outils nous ont aidés à regrouper les mots-clés en cluster de sens comparable (regroupement sémantique), ce qui présente deux avantages :
- cela réduit considérablement le temps humain nécessaire, nous permettant d'évaluer la pertinence de dizaines de clusters au lieu de milliers de mots-clés individuels ;
- cela nous fournit également des informations précieuses qui nous aideront à mieux comprendre et à analyser les résultats de nos prévisions futures.
Méthode de regroupement et d'analyse des mots-clés
Pour constituer nos groupes, une approche simple serait de s'appuyer directement sur la composition des mots. Le problème d'une telle approche est qu'elle serait capable de détecter les similitudes entre des mots comme "hôtel", "hotel" et "hôtellerie", mais ne parvient pas à reconnaître la proximité entre "auberge" et "hôtel".
Nous adoptons une approche plus sophistiquée, basée sur des modèles de langage pré-entraînés, qui permettent d'effectuer des regroupements sémantiques entre des mots qui n'ont pas nécessairement de lien étymologique. Nous convertissons notre corpus de mots-clés en données numériques, connues sous le nom d'embeddings, en utilisant le service d'OpenAI. En appliquant des techniques de regroupement sur les embeddings, nous sommes en mesure de regrouper efficacement les mots-clés ayant des significations similaires en un nombre restreint de clusters.
Mais il ne suffit pas de regrouper des mots-clés. Pour bien comprendre les résultats et leur impact sur le problème de prévision, nous devons comprendre ce que chaque cluster représente. C'est à ce stade que nous utilisons le modèle de language GPT-3.
La première question que nous avons posée à GPT-3 visait simplement à générer une courte description de chaque cluster. Cela nous permettra plus tard de facilement comprendre ce que nous utilisons comme données lors de la construction des modèles de prévisions ou lors de l'interprétation des résultats.
Write a short description that summarizes the cluster of keywords below:
[... list of keywords in cluster ...]
The description should be between 5 and 15 words.
La deuxième question visait à trier les clusters en fonction de leur probabilité d'être liés ou non à une réservation d'hôtel.
How likely is it that people who search the following keywords
in a search engine are considering booking a hotel in Alsace:
[... list of keywords in cluster ...]
Answer with only one word: 'very likely', 'likely', 'unlikely', 'very unlikely'
Les résultats présentés ci-dessous sont assez intéressants. La plupart des clusters sont liés à des villes spécifiques en Alsace, tandis que d'autres regroupent les hôtels par standing (hôtels de luxe ou hôtels bon marché) ou correspondent à des équipements spécifiques.
Cluster n°: 4
Description: Strasbourg hotels - various accommodation options.
Hotel related: Very Likely
Keywords examples: hotel holiday strasbourg, hotel lagrange strasbourg,
hotel strasbourg okko, hotel couvent strasbourg, hotel muller strasbourg
-----------------------
Cluster n°: 6
Description: Ribeauvillé, a charming French village, offers a variety of hotels
Hotel related: Very Likely
Keywords examples: resort barrière ribeauvillé, casino barriere ribeauvillé spa,
hotel proche ribeauvillé, hotel de la pepiniere ribeauville,
le clos st vincent ribeauville, hotel restaurant au lion ribeauvillé
-----------------------
Cluster n°: 16
Description: Luxury accommodation in the Bas-Rhin region
Hotel related: Very Likely
Keywords examples: residence royal mooslargue, le domaine du moulin ensisheim,
au cheval blanc ribeauvillé, la roseraie biebler jungholtz,
arbre vert soultzmatt, domaine de beaupré guebwiller elsass
-----------------------
Cluster n°: 15
Description: Hotels in Alsace offering Formule 1 accommodation
Hotel related: Very likely
Keywords examples: hotel formule 1 mulhouse aeroport, hotel formule 1 à strasbourg,
formule 1 bale mulhouse, formule 1 mulhouse, colmar hotel formule 1,
hotel formule 1 strasbourg sud la vigie
-----------------------
Cluster n°: 27
Description: Information on the town hall and municipal services in Alsace.
Hotel related: Very unlikely
Keywords examples: hotel de ville strasbourg, conseil municipal mulhouse,
mairie de strasbourg adresse, mairie de strasbourg telephone,
mairie de strasbourg horaires, mairie de strasbourg service etat civil
-----------------------
Le cluster n°27 n'a a priori aucun intérêt pour notre problème de prévision (cluster lié au terme "hôtel de ville"). Nous avons donc décidé de l'exclure de notre analyse.
Il est intéressant de noter que GPT-3 n'a répondu que par "très improbable" et "très probable" à la deuxième réponse, et a donné à chaque fois la même réponse que celle que nous aurions donnée.
Prévision
Nous pouvons maintenant confronter nos données de mots-clés aux séries d'activité hôtellière que nous voulons prévoir. Visuellement, on devine déjà des liens intéressants qui devront être confirmés par l'analyse statistique.
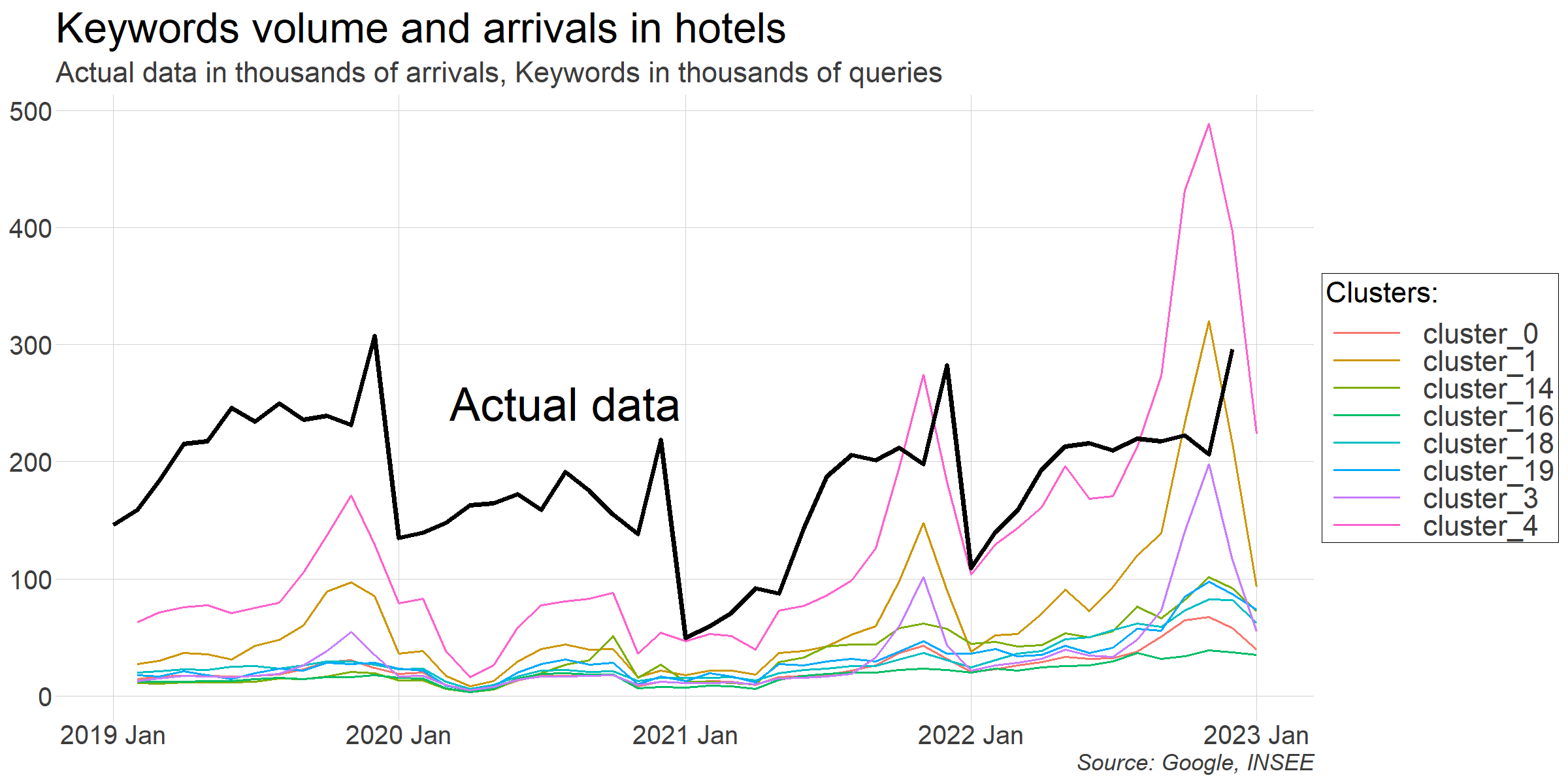
À ce stade, notre objectif est donc de déterminer si l'ajout des données Google permet d'obtenir des prédictions plus précises. Pour répondre à cette question, nous allons comparer deux modèles :
- un modèle de référence capable de reproduire les tendances et la saisonnalité des réservations et de prendre en compte la situation des ménages à travers l'enquête INSEE de confiance des ménages. (NB: seasonal ARIMAX )
- notre nouveau modèle, identique au premier, mais qui mobilise également un ou plusieurs indicateurs construits à partir des volumes de recherche Google.
Nous comparons les performance de prévision "out-of-sample" : nous estimons chaque modèle à un moment donné dans le passé à partir des données qui étaient réellement disponibles à ce moment-là. Puis nous produisons des prévisions et les comparons aux données réelles. Nous répétons ce processus sur un grand nombre de dates passées pour obtenir une idée de la performance de chaque modèle.
Les résultats sont assez clairs. Notre nouveau modèle, qui incorpore les données relatives aux mots-clés, surpasse le modèle de base de façon significative.
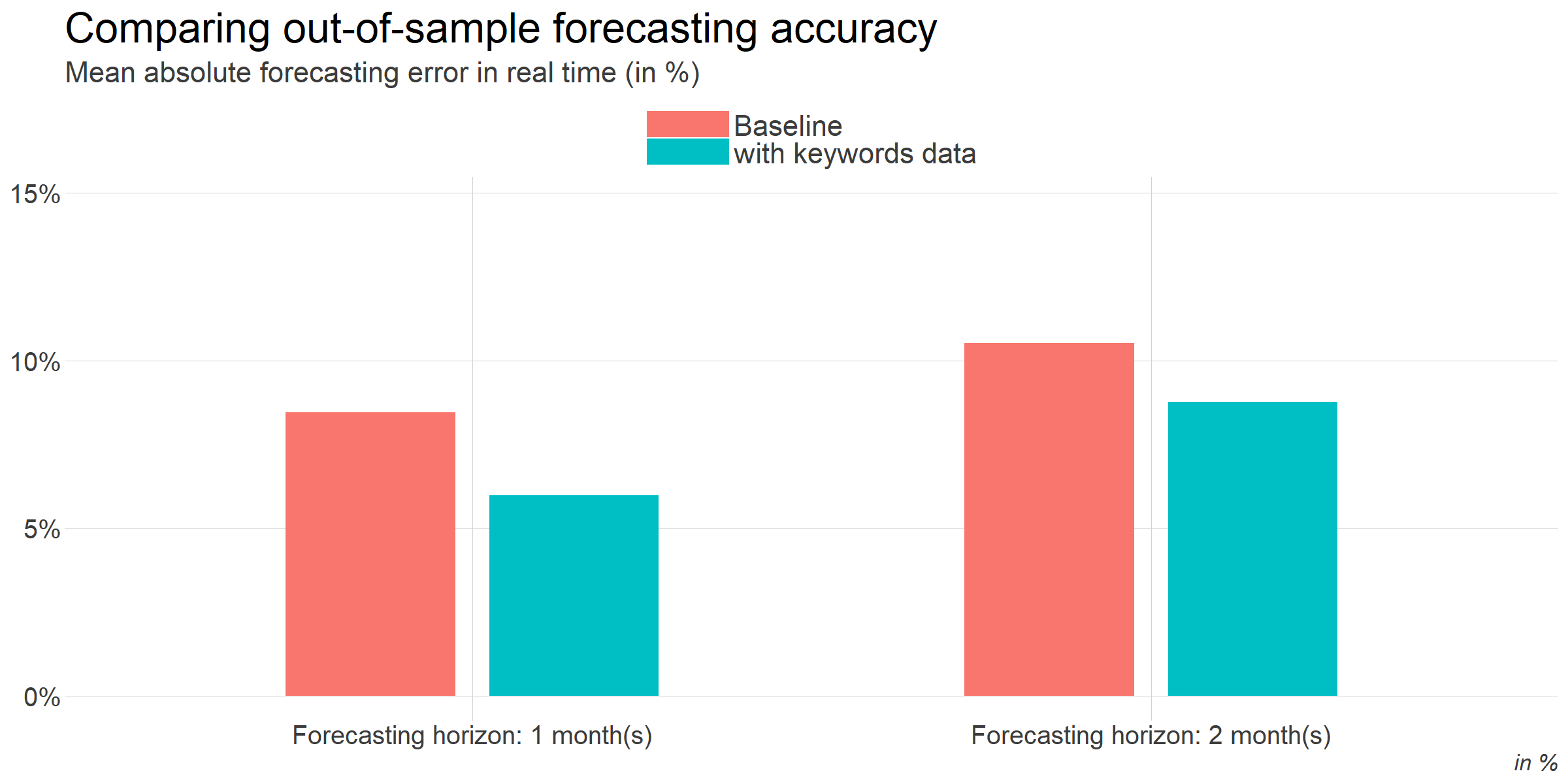
D'après notre expérience, battre la performance des modèles statistiques standards à court terme n'est pas si fréquent, même avec des données qui semblaient pertinentes a priori. C'est donc un résultat très positif.
Nous pouvons voir l'apport des données Google comme un moyen de gagner deux mois d'information par rapport aux données publiques disponibles. D'abord, les données de Google sont disponibles au milieu du mois suivant, contre plus d'un mois plus tard pour l'Insee. Ensuite, il semble que les requêtes de recherche sont un indicateur avancé (de nombreuses réservations en ligne sont effectuées des semaines ou des mois avant). Nous gagnons donc environ un mois supplémentaire grâce à cela.
Conclusion
Sur cet exemple simple, les résultats sont prometteurs et intéressants.
Bien sûr, il faut rester prudent et surveiller de près les performances réelles à l'avenir. Mais il semble assez probable que l'amélioration observée dans cet exemple (et sur d'autres cas sur lesquels nous avons aussi travaillé) puisse se généraliser à d'autres cas d'usage.
Dans tous les cas, ce type de données peut permettre d'affiner le diagnostic de la conjoncture récente et l'interprétabilité des scénarios de prévision.
Au vu de ces résultats positifs, nous prévoyons d'intégrer plus fréquemment ce type d'approches à nos solutions de prévision.
Contactez nous
Envoyez nous un message ci-dessous et nous vous répondrons.