How we used Google search data, language processing and GPT-3 to forecast touristic activity
Antoine Herlin, 2023 February 21
Abstract
This article shows how we used data from Google search queries to better predict and understand touristic activity in the Alsace region.
We used advanced language tools from OpenAI (embeddings models and GPT-3) to classify, sort and extract valuable insights from a large amount of keywords statistics.
The results are promising and it would be interesting to see if similar approaches can also be helpful in larger projects and for other sectors.
More generally, this is also an example of how high-level language models have become easily accessible to non-specialists and can be used to automate narrow intellectual tasks and develop new applications.

Photo by Julien Verneaut on Unsplash
Background and objectives
Our goal is to understand the recent past and to forecast the near future of touristic activity in the French region of Alsace. In this simple example we will focus on a sub-problem of the project: hotel reservations.
Data about hotel reservations is publicly available from the French statistical institute (INSEE). It is published monthly, usually around 40 days after the end of the month.
Let's look at recent data:
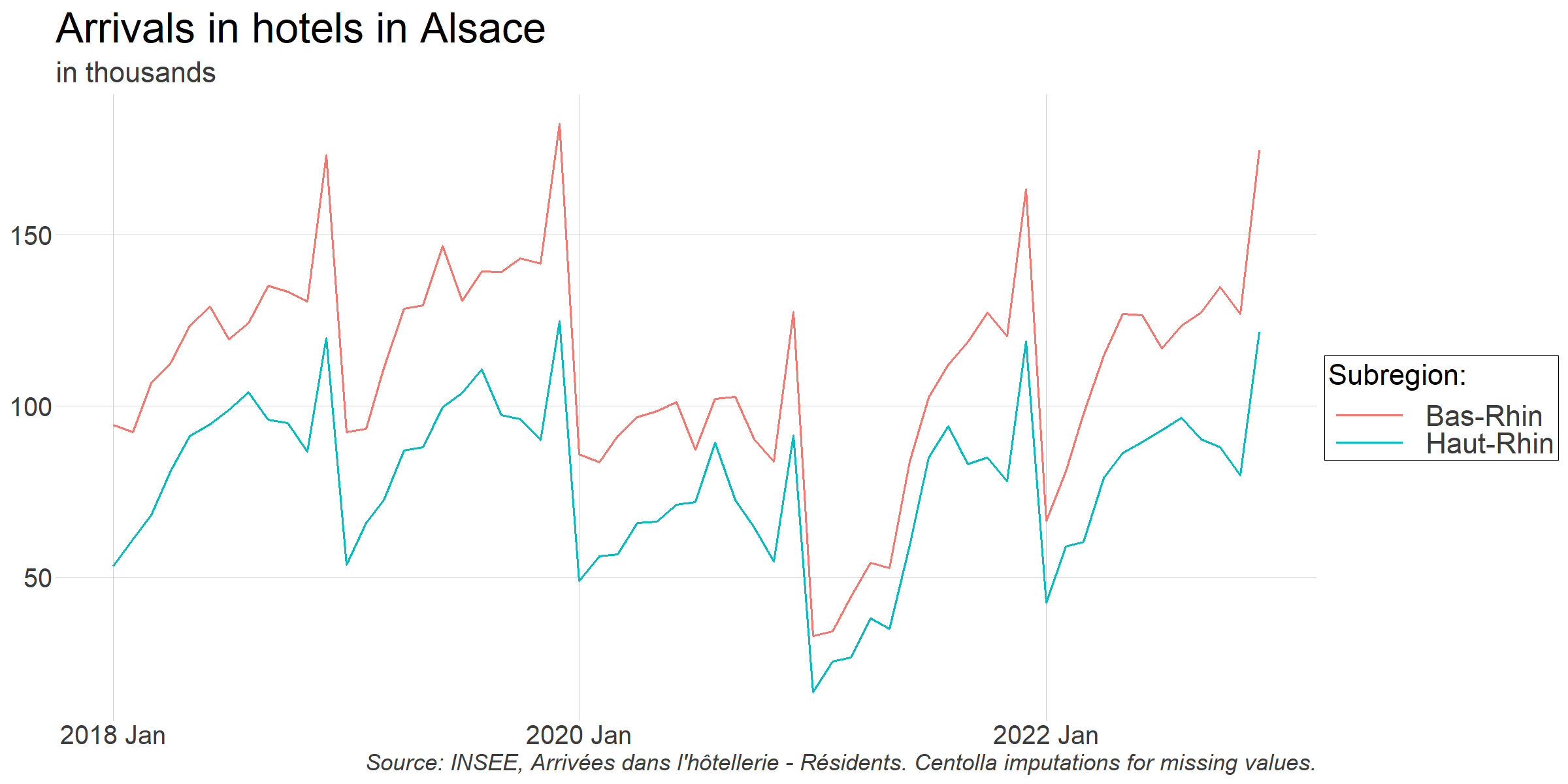
We can notice there is a lot of variability in the series!
- First, as expected, touristic activity is always very seasonal. The summer is quite busy while the beginning of the year isn't. In the case of Alsace, the huge peak we observe in December is due to seasonal events that attract lots of tourist (Christmas markets, especially in Strasbourg).
- Second, we can clearly see the impact of the pandemic and lockdowns. Hotel arrivals have been much lower than normal from the beginning of 2020 to mid-2021.
Variability is probably good news here. We will be able to test whether data from search engine is helpful to explain seasonal changes as well as the specific period of the pandemic.
Gathering search engine data
It seems quite reasonable to think there should be a correlation between some search engine queries and hotel reservations. Among people that are planning a trip to Alsace, many of them are likely to google terms like "hotel alsace" or "hotel strasbourg".
But to test this assumption we first need to collect data.
There are many tools that help gathering metrics for large number of keywords. (either directly from Google or using third-party applications ). Initially we got data for around 10 000 keywords that may be related to hotels in the Alsace region. At this point we don't need to be too specific. We will later filter keywords that appear irrelevant or that don't seem helpful for predictions.
Here are examples of search volumes for some of the keywords that we got:
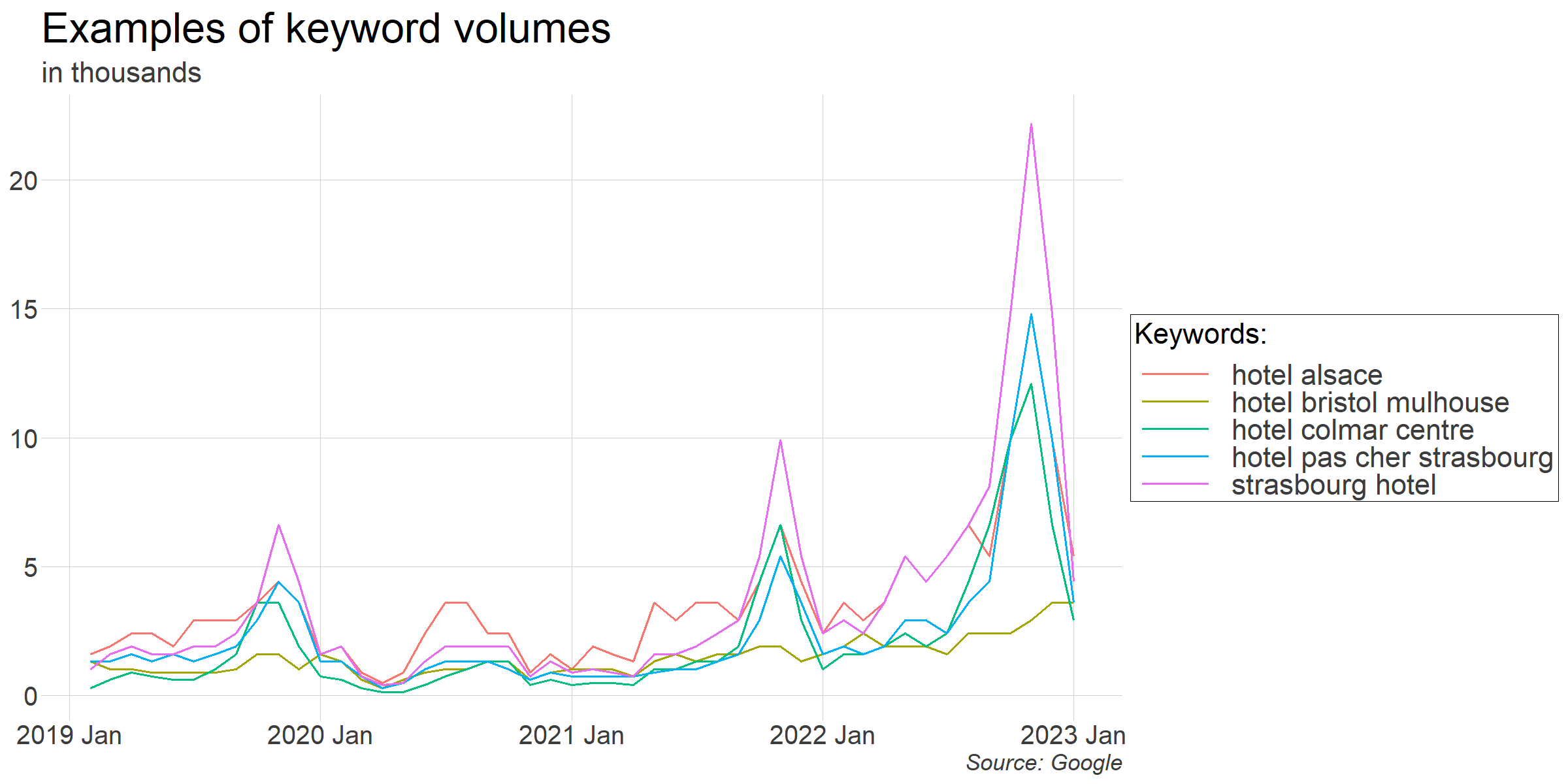
How can we use our keywords data?
So now we have lots of keywords data at hand, which can be both a blessing and a curse. While it's great to have access to such a wealth of information, the challenge lies in identifying what data is actually relevant to our objective.
To sort through the information, our first approach was to use a statistical method that would allow us to keep the keywords that lead to models with the best predictions.
However, there is a high risk of overfitting in this scenario as we have a lot of explanatory data for just a few observations. This means that it would be easy to build models that fit the past perfectly but fail to produce accurate predictions when faced with new data in the future.
To mitigate this risk, we need to bring some common sense into the process. We need to choose subsets of keywords that seem to have a plausible link with hotel reservations. This task is straightforward for humans, but when you need to do it for thousands or even hundreds of thousands of keywords, it becomes overly time-consuming.
To overcome this challenge, we decided to use language processing tools and language generation models in our project. These tools helped us regroup the keywords in cluster of comparable meaning (semantic clustering), which has 2 advantages:
- this makes our work more manageable, allowing us to evaluate the relevancy of a few dozens of clusters instead of thousands of individual keywords;
- it also provides us with valuable insights that will help us better understand and analyse the results of our future forecasts.
Uncovering relevant keywords for hotel activity forecasting with a semantic clustering approach
Our journey towards finding relevant keywords for hotel activity forecasting begins with regrouping similar keywords into one semantic cluster. A traditional approach based on word composition is able to detect similarities between words like "hotel", "hôtel", and "hotellerie", but falls short in recognizing the closeness between "auberge" and "hotel".
To overcome this challenge, we take a different approach. We convert our corpus of keywords into numerical data, known as embeddings, using OpenAI's service. By applying clustering techniques on the embeddings, we are able to effectively regroup keywords with similar meanings.
But just grouping keywords is not enough. To fully understand the results and their impact on the broader problem we are studying, we need to understand what each cluster represents. This is where GPT-3 comes into play. With precise prompts and ample context, we use GPT-3 to gain insights into each cluster.
The first question we asked GPT-3 simply aimed at generating a short description that would help us understand what each cluster is about when we build a forecasting model or try to understand the forecasts.
Write a short description that summarizes the cluster of keywords below:
[... list of keywords in cluster ...]
The description should be between 5 and 15 words.
The second question aimed at sorting the clusters based on their likelihood of being hotel-related or not.
How likely is it that people who search the following keywords
in a search engine are considering booking a hotel in Alsace:
[... list of keywords in cluster ...]
Answer with only one word: 'very likely', 'likely', 'unlikely', 'very unlikely'
The results presented below are quite interesting. Most clusters are related to specific cities in Alsace, while others are related to the class of hotels, such as luxury or cheap, and specific amenities.
Cluster n°: 4
Description: Strasbourg hotels - various accommodation options.
Hotel related: Very Likely
Keywords examples: hotel holiday strasbourg, hotel lagrange strasbourg,
hotel strasbourg okko, hotel couvent strasbourg, hotel muller strasbourg
-----------------------
Cluster n°: 6
Description: Ribeauvillé, a charming French village, offers a variety of hotels
Hotel related: Very Likely
Keywords examples: resort barrière ribeauvillé, casino barriere ribeauvillé spa,
hotel proche ribeauvillé, hotel de la pepiniere ribeauville,
le clos st vincent ribeauville, hotel restaurant au lion ribeauvillé
-----------------------
Cluster n°: 16
Description: Luxury accommodation in the Bas-Rhin region
Hotel related: Very Likely
Keywords examples: residence royal mooslargue, le domaine du moulin ensisheim,
au cheval blanc ribeauvillé, la roseraie biebler jungholtz,
arbre vert soultzmatt, domaine de beaupré guebwiller elsass
-----------------------
Cluster n°: 15
Description: Hotels in Alsace offering Formule 1 accommodation
Hotel related: Very likely
Keywords examples: hotel formule 1 mulhouse aeroport, hotel formule 1 à strasbourg,
formule 1 bale mulhouse, formule 1 mulhouse, colmar hotel formule 1,
hotel formule 1 strasbourg sud la vigie
-----------------------
Cluster n°: 27
Description: Information on the town hall and municipal services in Alsace.
Hotel related: Very unlikely
Keywords examples: hotel de ville strasbourg, conseil municipal mulhouse,
mairie de strasbourg adresse, mairie de strasbourg telephone,
mairie de strasbourg horaires, mairie de strasbourg service etat civil
-----------------------
One cluster (n° 27) stands out as having no relevance to our objective and can be safely disregarded. It turns out, the cluster was formed by keywords related to municipality services and was mistakenly captured due to the French word "Hôtel de ville" being a synonym for "Town Hall".
Interestingly enough, GPT-3 only answered by "very unlikely" and "very likely" to the second question. And gave each time the same answer as the one we would have given.
Forecasting
Now we are ready to confront our keyword data to the actual series we want to predict. At first glance, the data appears promising but visual correlations don't always translate into accurate forecasting models.
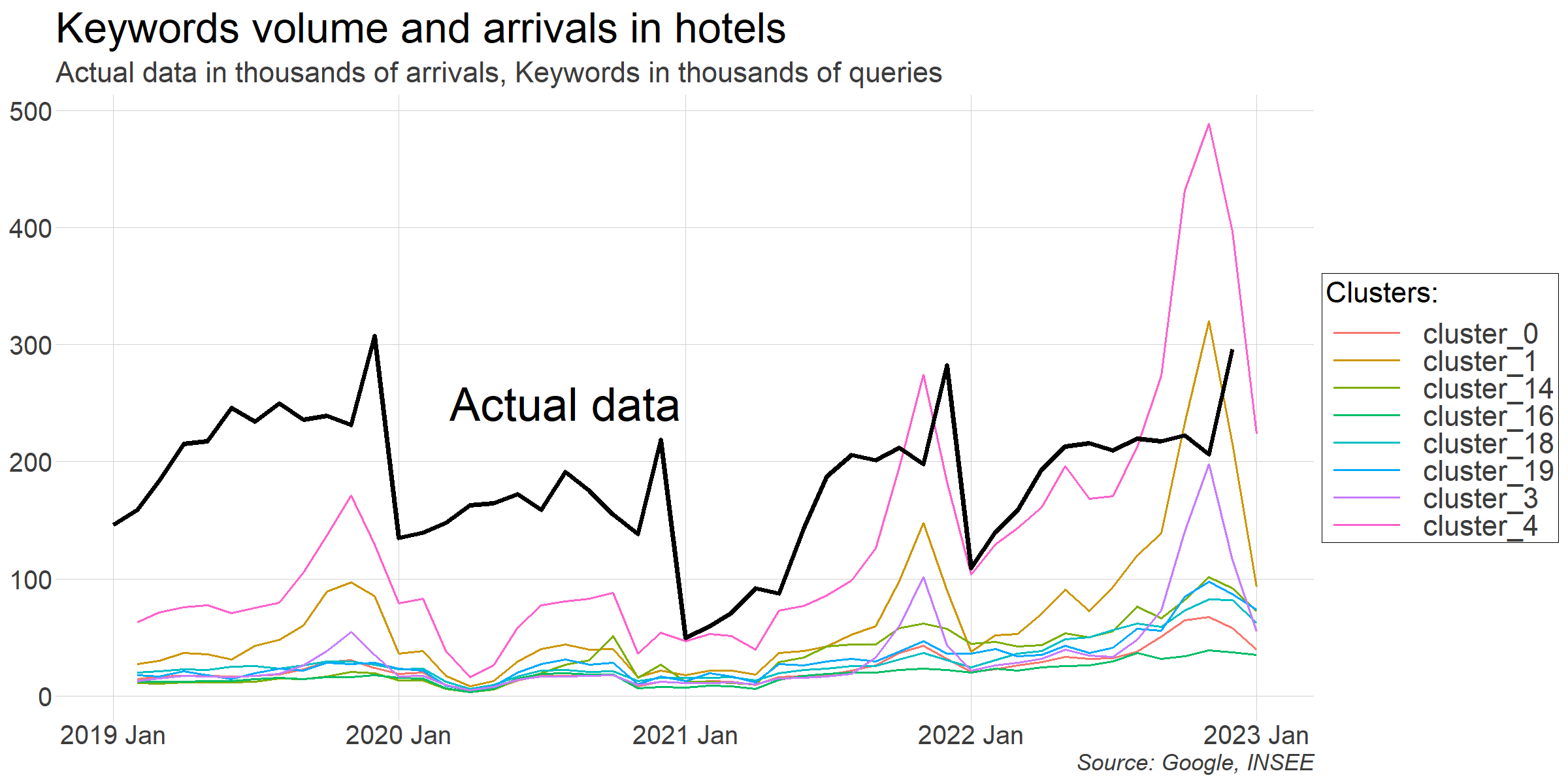
Our goal is to determine if including Google data in the model will lead to more accurate predictions. To answer that question, we are going to compare two models:
- our baseline model (what we would have done without keyword data). This model is able to reproduce the trends and specific seasonality as well as changes in consumer confidence (NB: seasonal ARIMAX )
- our new model is the same as the first one, but with additional predictors built from the cluster of keywords.
We compare the forecasting performance of each model with out-of-sample evaluation. We estimate each model at some point in the past with data that was actually available at that time, we produces forecasts and compare them to the actual data. Then, we repeat this process for many dates in the past.
The results are quite clear. Our new model, incorporating the keyword data, outperforms the baseline model by a significant margin.
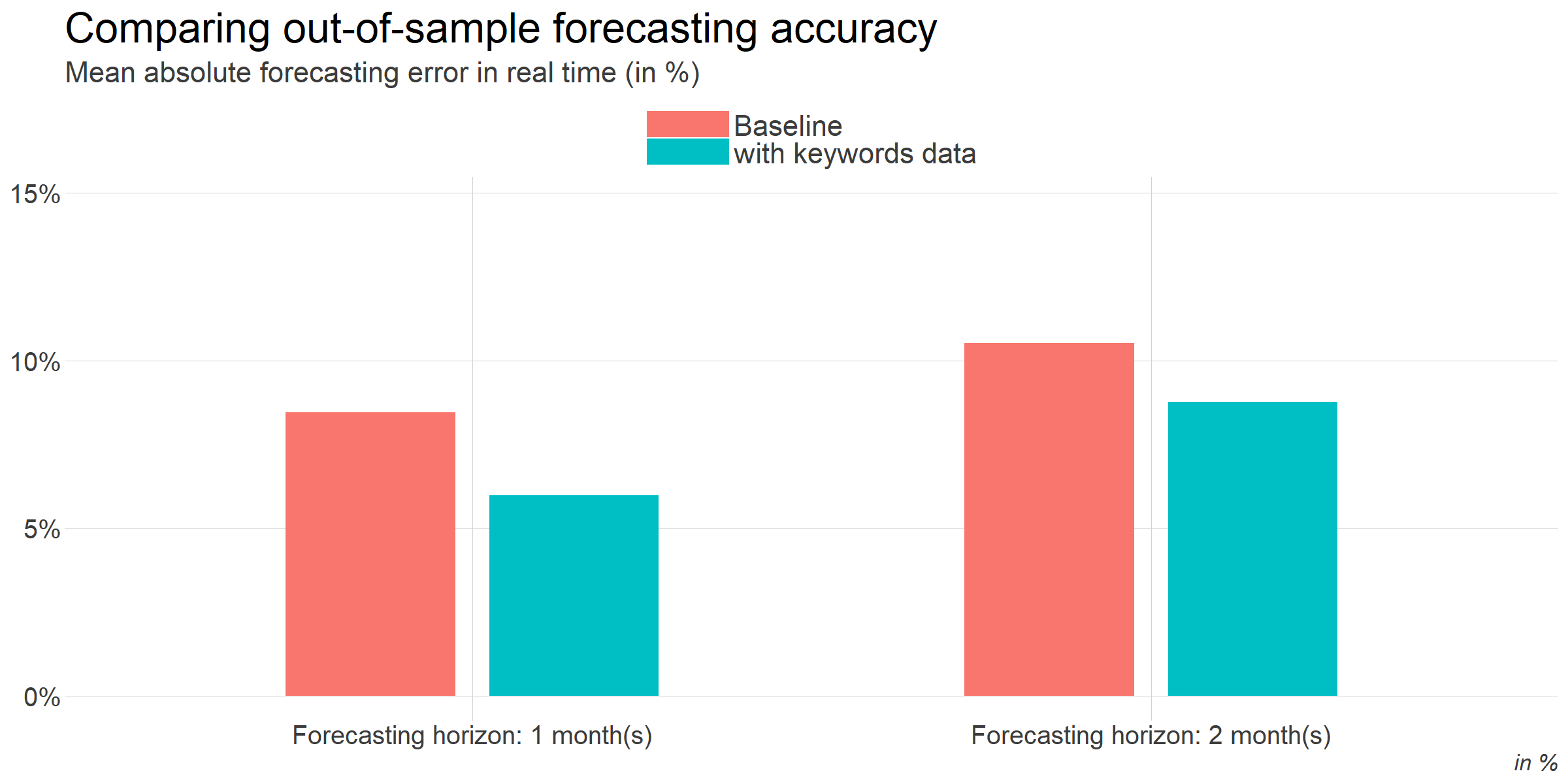
In our experience, beating the performance of standards statistical models in the short run is not that common even with data that looked relevant. So, this is very a positive result.
We can think of the keyword data as a way to foresee 2 months ahead compared to publicly available data. First, Google data is available in the middle of the next month, compared to more than a month later for Insee. Besides, it seems that search queries are a leading indicator of reservations (many online reservations are made weeks or months before the actual reservation). So, we gain approximately another month thanks to this.
Conclusion
The results of this simple example are intriguing and show a promising future for the integration of such tools in forecasting.
Of course, there is no guarantee that this will be replicable in many different sectors and we will need to monitor closely the actual performance in the future. But we think there is reasonably strong evidence that using this kind of approach can in many cases lead to improved predictions and greater understanding of forecasts.
In light of these positive results, we plan to make increasing use of these tools in the future.
Centolla develops customized forecasting solution for all sectors and all horizons. Get in touch: contact@centolla.org
Contactez nous
Envoyez nous un message ci-dessous et nous vous répondrons.